前言
# 前言
官方镜像下载地址: Centos (opens new window),hadoop (opens new window),Java (opens new window) Centos为CentOS-7-x86_64-DVD-2009 (opens new window) Hadoop为hadoop-3.3.1.tar.gz (opens new window) Java为jdk-8u301-linux-x64.tar.gz (opens new window) PS:Hadoop3.X Java最低版本为1.8 纯原生态安装,非CDH和HDP,或是Ambari
# 预先设置
修改主机名hostname
hostnamectl set-hostname docloud001.dataojo.com
修改/etc/hosts文件,host文件用户映射ip,docloud001.dataojo.com会解析成当前主机
vi /etc/hosts
# 这里我除了修改127.0.0.1里的localhost localhost.localdomain
127.0.0.1 localhost localhost.docloud001.dataojo.com localhost4 localhost4.localdomain4
::1 localhost localhost.docloud001.dataojo.com localhost6 localhost6.localdomain6
重启服务器
# 关闭防火墙
# 关闭
systemctl stop firewalld
# 禁止开机自启
systemctl disable firewalld
# 创建hadoop用户
# 创建用户并使用 /bin/bash 作为shell
useradd -m hadoop -s /bin/bash
# 给hadoop用户设置密码,若提示密码无效,不用管,接着输入一次即可
passwd hadoop
# 给hadoop增加执行权限
visudo
#98行 输入 :98 跳转至98行,增加一行 hadoop ALL=(ALL) ALL
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
# SSH安装免密登陆
# 单机免密登陆——linux配置ssh免密登录
检查是否安装SSH
systemctl status sshd
已安装会显示ssh服务的状态(actving),否则,执行下面命令安装
# -y表示全部同意,不用每次都按y
yum install openssh-clients -y
yum install openssh-server -y
测试是否可用
#按提示确认连接后,输入当前用户密码即可,初始没有密码会提示创建密码
ssh localhost
设置无密码登录
#~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限
此时再用 ssh localhost 命令,无需输入密码就可登陆
# 安装Hadoop-3.3.0.tar.gz
上传至服务器,或者从服务器中下载 找个目录解压,比如/opt下
# -C 是指定解压目录
tar -zxvf hadoop-3.3.0.tar.gz -C /opt
解压完检查hadoop是否可用
#切换到hadoop的安装目录执行, 成功则显示版本信息
cd /opt/hadoop-3.3.0
./bin/hadoop version

可能会出现这些问题,在vim ~/.bashrc添加:
export HADOOP_HOME=/opt/hadoop-3.3.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
这里我们可以将hadoop也加入环境变量,就不需要每次到bin目录下执行
# 编辑profile文件
vi /etc/profile
# 增加hadoop环境变量
export HADOOP_HOME=/opt/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 保存后刷新下环境变量
source /etc/profile
# 运行
# 伪分布式
# 1.修改配置文件
Hadoop 的配置文件位于 安装目录下 /etc/hadoop/ 中
[root@hadoop1 hadoop]# pwd
/opt/hadoop-3.3.0/etc/hadoop
伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
#修改配置文件hadoop-env.sh
# set to the root of your Java installation
export JAVA_HOME=/usr/java/jdk
#修改配置文件 core-site.xml
<configuration>
<!--指定Hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/tmp</value>
</property>
<!--指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://docloud001.dataojo.com:9000</value>
</property>
</configuration>
#修改配置文件 hdfs-site.xml,
#搭建集群后,hadoop本身自带了一个webUI访问页面
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
# 2.格式化NameNode
./bin/hdfs namenode -format
# 3.开启 NaneNode 和 DataNode 进程
./sbin/start-dfs.sh
#启动完成后,可以通过命令 jps 来判断是否成功启动
[hadoop@localhost hadoop-3.3.0] jps
32081 NameNode
32561 Jps
32234 DataNode
#停止
./sbin/stop-dfs.sh
如果出现 ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. 解决方法:
cd /opt/hadoop-3.3.0/etc/hadoop vim /hadoop-env.sh export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
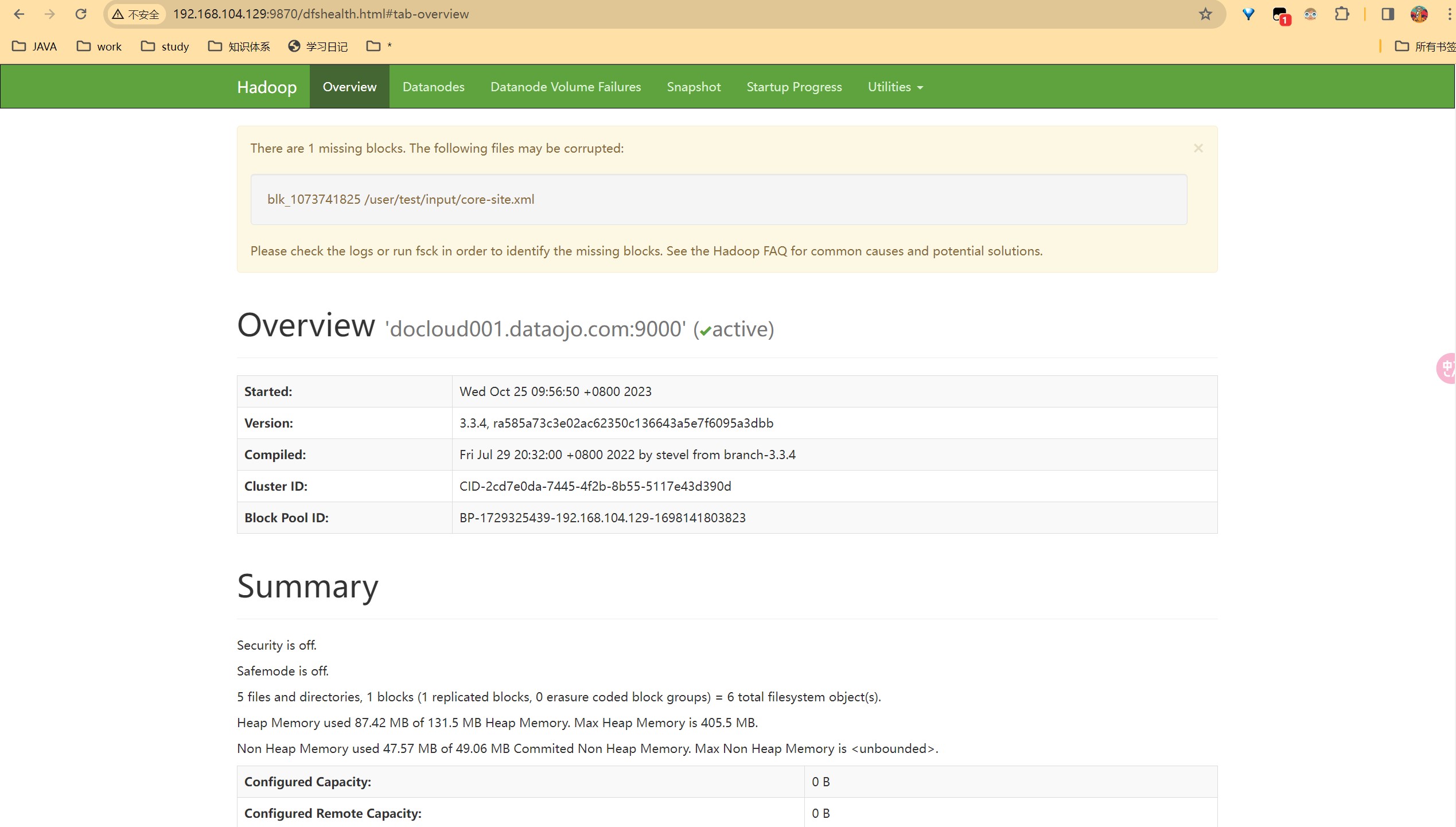
日志文件输出在 安装目录下的logs文件夹中。 可以访问web页面,前面配置过的 http://localhost:9870/
# 4. 操作集群
- 在HDFS系统上创建一个input文件夹
./bin/hdfs dfs -mkdir -p /user/test/input
- 将测试文件内容上传到文件系统上
./bin/hdfs dfs -put input/core-site.xml /user/test/input/
- 查看上传的文件是否正确
./bin/hdfs dfs -ls /user/test/input/
./bin/hdfs dfs -cat /user/test/input/core-site.xml
- 运行mapReduce程序
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/test/input/core-site.xml /user/test/output/
./bin/hdfs dfs -cat /user/test/output/*
在浏览器中查看: