2018上
承灿 2023/9/7
# 1
在寻址方式中,将操作数的地址放在寄存器中的方式称为( )。
A. 直接寻址
B. 间接寻址
C. 寄存器寻址
D. 寄存器间接寻址
将操作数的地址放在寄存器中的方式称为寄存器寻址。在寄存器寻址方式中,操作数的地址保存在寄存器中,指令通过访问该寄存器来获取操作数的值。
使用寄存器寻址可以有效地减少内存访问次数,提高程序的执行效率。通常情况下,寄存器寻址是 CPU 中最快的一种寻址方式,因为它不需要访问内存,而是直接通过访问寄存器来获取操作数的值。
在寄存器寻址方式中,通常会使用一些特殊的寄存器来保存操作数的地址,例如基址寄存器和偏移量寄存器。基址寄存器用于保存操作数的起始地址,而偏移量寄存器则用于保存操作数相对于基址的偏移量,通过这两个寄存器的组合,可以实现对任意地址的访问。
( )是使用电容存储信息且需要周期性地进行刷新的存储器。
A. ROM
B. DRAM
C. EPROM
D. SRAM
(14)是构成我国保护计算机软件著作权的两个基本法律文件。单个自然人的软件著作权保护期为(15)。
A. 50年
B. 自然人终生及其死亡后50年
C. 永久限制
D. 自然人终生
16
下列攻击行为中,( )属于被动攻击行为。
A. 拒绝服务攻击
B. 窃听
C. 伪造
D. 篡改消息
19
( )是可以检错和纠错的校验码。
A. 海明码
B. 原码
C. 反码
D. 补码
海明码是可以检错和纠错的校验码。
海明码是一种多位冗余校验码,通过在数据中添加冗余位来实现错误检测和纠错。具体来说,海明码在原始数据的基础上添加一些控制位(也称为校验位),用于检测和纠正可能出现的错误。
在海明码中,每个控制位对应一个数据位或多个数据位的异或和。当接收方收到数据后,会重新计算每个控制位的异或和,并将其与发送方发来的校验位进行比较。如果有控制位的值不匹配,则说明数据出现了错误,接收方可以根据控制位的位置和值,确定出错的数据位,并进行纠正。
相比于其他校验码,如奇偶校验、循环冗余校验等,海明码能够检测和纠正更多的错误,因此被广泛应用于数据通信、存储等领域。
20
对于十进制数-1023,至少需要( )个二进制位表示该数(包括符号位)。
A. 8
B. 9
C. 10
D. 11
对于十进制数-1023,至少需要11个二进制位来表示该数(包括符号位)。
首先,我们需要考虑符号位。对于有符号数,最高位用来表示正负号,0表示正数,1表示负数。所以,一位被用来表示符号位。
接下来,我们需要确定能够表示-1023的二进制位数。-1023的绝对值在二进制中可以表示为:10000000001。
这个二进制数共有11位,因此至少需要11个二进制位来表示-1023(包括符号位)。
因此,选项 D. 11 是正确答案。
21
对于十六进制数5C,可用算式( )计算与其对应的十进制数。
A. 5*16+12
B. 12*16+5
C. 5*16-12
D. 12*16-5
24
“从减少成本和缩短研发周期考虑,为使系统能运行在不同的微处理器平台上,要求能针对硬件变化进行结构与功能上的配置”属于嵌入式操作系统的( )特点。
A. 可定制
B. 实时性
C. 可靠性
D. 易移植性
25
在某单处理机系统中,采用先来先服务调度算法。某一时刻,该系统中有4个进程P1、P2、P3、P4 (假设进程按此顺序到达),其中P1为运行状态,P2为就绪状态,P3和P4为等待状态;且P3等待打印机,P4等待扫描仪。若P1释放了扫描仪,则下列进程中( )处于运行状态。
A. P1
B. P2
C. P3
D. P4
根据题目描述,采用先来先服务调度算法,进程P1为运行状态,P2为就绪状态,P3和P4为等待状态,且P3等待打印机,P4等待扫描仪。
如果P1释放了扫描仪,那么下一个处于运行状态的进程应该是就绪状态中最早到达的进程。根据题目描述,P2是就绪状态中最早到达的进程,因此,答案是B. P2。
26
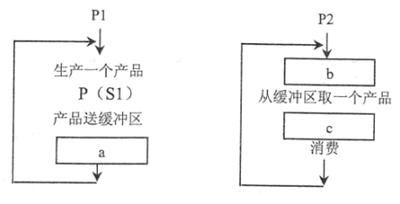
某系统中有一个缓冲区,进程P1不断地生产产品送入缓冲区,进程P2不断地从缓冲区中取出产品消费,用P、V操作实现进程间的同步模型如下图所示。假设信号量S1的初值为1,信号量S2的初值为0,那么a、b、c处应分别填( )。
A. V (S2)、P (S1)、V (S1)
B. V (S2)、P (S2)、V (S1)
C. P (S2)、V (S1)、V (S2)
D. P (S2)、V (S2)、V (S1)
根据题目,进程P1不断地生产产品送入缓冲区,进程P2不断地从缓冲区中取出产品消费。同时,信号量S1的初值为1,表示缓冲区有一个位置可以进行生产操作;信号量S2的初值为0,表示缓冲区没有产品可以进行消费操作。
根据上述同步模型,进程P1在生产产品时需要执行P(S1)操作,以获取S1的使用权,表示缓冲区可以进行生产操作;当完成生产后,需要执行V(S2)操作,以释放S2的使用权,表示缓冲区中有了新的可消费产品。因此,答案中应选择选项A。
进程P2在消费产品时需要执行P(S2)操作,以获取S2的使用权,表示缓冲区中有可消费的产品;当完成消费后,需要执行V(S1)操作,以释放S1的使用权,表示缓冲区有了新的空闲位置。因此,选项B、C、D都是错误的。
29
下面关于编译和解释的说法中,正确的是( )。
①编译是将高级语言源代码转换成目标代码的过程
②解释是将高级语言源代码转换为目标代码的过程
③在编译方式下,用户程序运行的速度更快
④在解释方式下,用户程序运行的速度更快
A. ①③
B. ①④
C. ②③
D. ②④
正确的说法是:
①编译是将高级语言源代码转换成目标代码的过程
④在解释方式下,用户程序运行的速度更快
解释:
①编译是将高级语言源代码转换成目标代码的过程。编译器会将整个源代码一次性地转换成目标机器代码,生成可执行文件,因此编译是一个一次性的过程。
④在解释方式下,用户程序运行的速度更快。在解释方式下,源代码逐行解释并执行,因此程序的执行速度更快,但解释过程会稍微降低程序的执行效率。
35
某循环队列Q的定义中用front和rear两个整型域变量表示队列状态,其中front 指示队头元素的位置、rear指示队尾元素之后的位置(如下图所示,front的值为5、rear 的值为1)。若队列容量为M(下图中M=6),则计算队列长度的通式为( )。
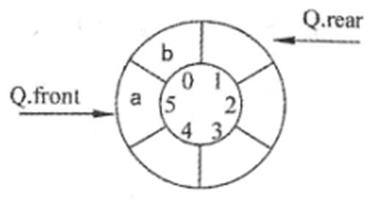
A. (Q.front - Q.rear)
B. (Q.front - Q.rear + M)%M
C. (Q.rear - Q.front)
D. (Q.rear - Q.front + M)%M
根据权值集合{0.30, 0.25, 0.25, 0.12, 0.08}构造的哈夫曼树中,每个权值对应哈夫曼树中的一个叶结点,( )。
A. 根结点到所有叶结点的路径长度相同
B. 根结点到权值0.30和0.25所表示的叶结点路径长度相同
C. 根结点到权值0.30所表示的叶结点路径最长
D. 根结点到权值0.25所表示的两个叶结点路径长度不同
40
对一棵二叉排序树进行( )遍历,可得到该二叉树中结点关键字的有序序列。
A. 先序
B. 中序
C. 后序
D. 层序
46
在UML中,行为事物是模型中的动态部分,采用动词描述跨越时间和空间的行为。( )不属于行为事物。
A. 交互
B. 状态机
C. 关联
D. 活动
54
对软件的过分分解不会导致( )。
A. 模块独立性变差
B. 软件功能减少
C. 接口复杂度增加
D. 总的开发工作量增加
57
数据库系统中,构成数据模型的三要素是( )。
A. 数据类型、关系模型、索引结构
B. 数据结构、网状模型、关系模型
C. 数据结构、数据操作、完整性约束
D. 数据类型、关系模型、完整性约束
62
假设事务T1对数据D1加了共享锁,事务T2对数据D2加了排它锁,那么( )。
A. 事务T2对数据D1加排它锁成功
B. 事务T1对数据D2加共享锁成功,加排它锁失败
C. 事务T1 对数据D2加排它锁或共享锁都成功
D. 事务T1 对数据D2加排它锁和共享锁都失败
63
某书的页码为1,2,3,...,共用数字900个(一个多位数页码包含多个数字), 据此可以推断,该书最大的页码为( )。
A. 237
B. 336
C. 711
D. 900
64
已知函数y=f(X)在X1和X2处的值分别为y1和y2,其中,X2>X1且X2-X1比较小(例如0.01),则对于(x1,x2)区间内的任意X值,可用线性插值公式( )近似地计算出f(x)的值。
A. y1+(y2-y1)(x-x1)/(x2-x1)
B. x1+(y2-y1)(x-x1)/(x2-x1)
C. y2+(y2-y1)(x2-x1)/(x-x1)
D. x2+(x2-x1)(x-x1)/(y2-y1)
70
当出现网络故障时,一般应首先检查( )。
A. 系统病毒
B. 路由配置
C. 物理连通性
D. 主机故障
71
( ) can help organizations to better understand the information contained within the data and will also help identify the data that is most important to the business and future business decisions.
A. Data processing system
B. Big Data analytics
C. Cloud computing
D. Database management
72
After analyzing the source code, ( ) generates machine instructions that will carry out the meaning of the program at a later time.
A. an interpreter
B. a linker
C. a compiler
D. a converter
73
algorithm specifies the way to arrange data in a particular order.
A. Search
B. Random
C. Sorting
D. Merge
74
As each application module is completed, it undergoes ( ) to ensure that it operates correctly and reliably .
A. unit testing
B. integration testing
C. system testing
D. acceptance testing
75
( ) is the process of transforming information so it is unintelligible to anyone but the intended recipient.
A. Encryption
B. Decryption
C. Security
D. Protection
 答案
答案